
ウェブサイトを作成しても、検索エンジンのクローラーと呼ばれる巡回ロボットがお持ちのページを巡回しなければ検索結果に表示される事はありません。
robots.txtはクローラーの巡回を拒否する際に使用しますので、SEO対象のページをブロックしてしまわないように記述内容を確認する必要があります。
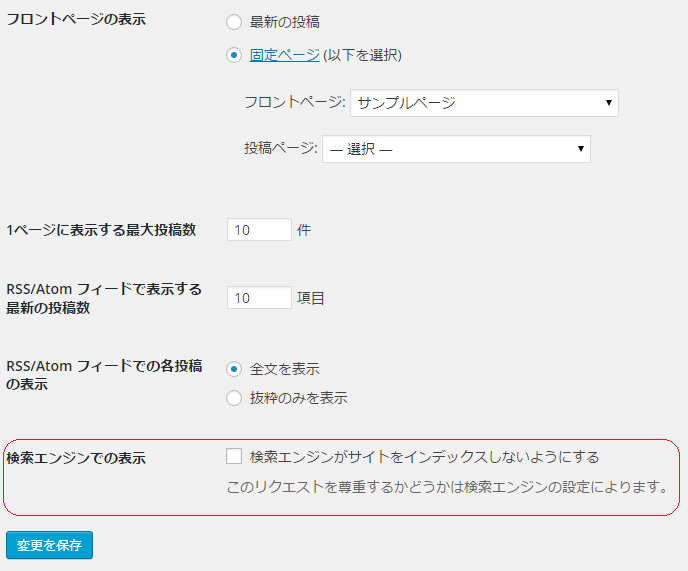
特にWordPressをご利用の方の場合、「検索エンジンがサイトをインデックスしないようにする」設定のままウェブサイトを立ち上げてしまう場合がございます。その場合は、WordPressの管理画面の左メニュー「設定」をクリックし、「表示設定」をクリックして、「検索エンジンがサイトをインデックスしないようにする」のチェックを外して「変更を保存」ボタンをクリックしてください。
robots.txtの使い方
検索結果に載せたくないページがあった場合には、robots.txtを記述して検索エンジンがページを巡回する事を拒否することができます。
一般的には、CMSの管理画面やECサイトのショッピングカート内へのクロールをブロックして、検索結果に載せないようにします。
robots.txtの記述方法 使い方と注意点も参考までにご確認ください。
robots.txtの記述内容の解説
User-agent: *
Disallow: /wp-admin/WordPressの場合は、上記のように設定されている事が多いと思います。
これは、全てのクローラーに対して、/wp-admin/へのアクセスをブロックし、管理画面を検索結果に載せない為の記述です。User-agent
User-agentは、ユーザーエージェントと読みます。
ここに対象の検索エンジンのクローラーを指定します。
各検索エンジンクローラーのユーザーエージェントは、以下のページから確認できます。
http://www.robotstxt.org/db.htmlDisallow
Disallowは、指定したURLへの巡回をブロックします。
ウェブサイト公開前であれば、「/」スラッシュでウェブサイト全体の巡回をブロックします。
特定のディレクトリ内を全てブロックする場合は、「/sample/」のように記述します。(/sample/ディレクトリ内を全てブロックする記述です。)
「/privacy.php」のように特定のページ単位でも指定ができます。
他にもAllowという記述をする事もあります。これは、Disallowでブロックされたディレクトリ内の特定の子ディレクトリのURLのクロールのみを許可する場合に記述します。
より詳しい記述方法は、「robots.txt ファイルを作成する」をご確認ください。
このようにrobots.txtはクローラーの道筋をブロックするバリケードのような役割を持ちます。
一方でクローラーの巡回を効率化する標識のような役割を果たすものでXMLサイトマップというファイルがあります。
XMLサイトマップでクローラーを呼び込む
XMLサイトマップは検索エンジンがあなたのウェブサイトを巡回する際に、参考とするファイルです。正しくXMLサイトマップを設定する事で、クローラーの巡回が効率化されます。
XMLサイトマップは定期的に更新
新たにページを追加したり、既存のページの内容を大きく変更した場合には、XMLサイトマップを更新して、検索エンジンにウェブサイトの状態を知らせましょう。
このように運用することで、検索結果にも素早く反映されるようになります。
XMLサイトマップの生成からアップロード、検索エンジンへの通知を定期的に行う事ができるツールもあります。Sitemap Creatorは、一度設定しておけば自動的にXMLサイトマップを更新してくれる為、おすすめできるツールです。